11月27日,浪潮电子信息产业股份有限公司在京发布“源2.0”基础大模型,并宣布全面开源。“源2.0”包括102B(1026亿)、51B(518亿)、2B(21亿)三种参数规模的模型,在编程、推理、逻辑等方面展示出了先进的能力。
基础大模型的关键能力是大模型行业和应用落地能力表现的核心支撑。在算法、数据和算力等方面,“源2.0”提出了新的改进方法并获得了能力的提升。
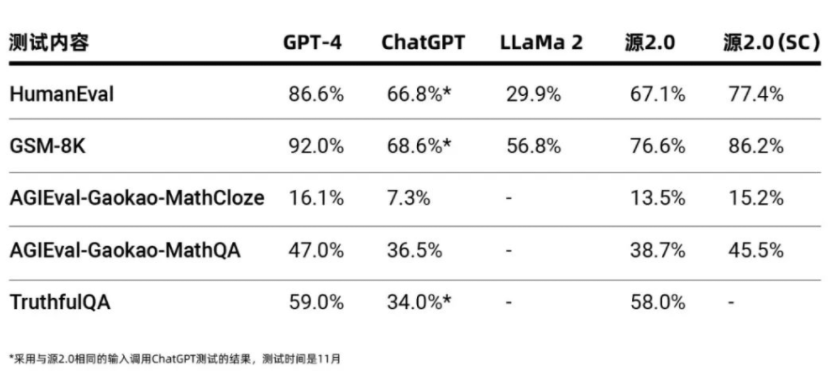
“源2.0”能力测评数据(浪潮信息供图)
如在算法方面,“源2.0”提出并采用了一种新型的注意力算法结构“局部注意力过滤增强机制”,让大模型在使用更少的训练算力、更小的模型参数的情况下,同样可以获得更高的模型精度和涌现能力;数据方面,降低了互联网语料内容占比,通过使用中英文书籍、百科、论文等资料,结合高效的数据清洗流程,为大模型训练提供了高质量的学科专业数据集和逻辑推理数据集。
作为千亿级基础大模型,“源2.0”在业界公开的评测上进行了代码生成、数学问题求解、事实问答方面的能力测试,测试结果显示,“源2.0”在多项模型评测中展示出了较为先进的能力表现。
“源2.0”采用全面开源策略,全系列模型参数和代码均可免费下载使用。“大模型的开源开放可以使不同模型之间共享底层数据、算法和代码,有利于打破大模型孤岛,促进模型之间协作和更新迭代;同时,有利于以更丰富的高质量行业数据反哺模型,打造更强的技术产品,加速商业化进程。目前,业内仍没有完全开源可商用的千亿大模型,我们希望‘源2.0’能够为国内外开发者、研究机构、科技企业提供坚实的底座和成长的土壤。”浪潮信息高级副总裁刘军说。
浪潮信息长期致力于人工智能算力基础设施产品的研发,2021年在业界率先推出了中文AI巨量模型“源1.0”,参数规模达2457亿,落地南京智算中心。此次发布的“源2.0”较前一版本实现了能力的全面提升。(记者温竞华)







